
Communiquer avec un machine distante (reseaux distants)
Bonjour,
Je développe dans quelques langages logiciels différents mais je n'ai jamais trop creusé le développement réseau. Aujourd'hui, je me lance, mais je rencontre des difficultés. Aucun tutoriel ou article n'explique comment acheminer des données entre deux réseaux distants. J'ai une base d'application de chat python, mais seulement en LAN.
Est-ce qu'il y a un rapport avec IPv4 - IPv6 pour résoudre mon problème ou je m'égare ?? Ça a peut être un rapport avec les protocoles enfin bref, merci d'avance pour vos réponses.
Je développe dans quelques langages logiciels différents mais je n'ai jamais trop creusé le développement réseau. Aujourd'hui, je me lance, mais je rencontre des difficultés. Aucun tutoriel ou article n'explique comment acheminer des données entre deux réseaux distants. J'ai une base d'application de chat python, mais seulement en LAN.
Est-ce qu'il y a un rapport avec IPv4 - IPv6 pour résoudre mon problème ou je m'égare ?? Ça a peut être un rapport avec les protocoles enfin bref, merci d'avance pour vos réponses.
A voir également:
- Communiquer avec un machine distante (reseaux distants)
- Machine virtuelle - Guide
- Carte bancaire machine à laver ✓ - Forum Matériel & Système
- Carte bleu passé a la machine à laver ✓ - Forum Loisirs / Divertissements
- Interconnexion de sites distants - Forum Réseau
- Sandra a décidé de mieux contrôler son image et sa présence sur différents réseaux sociaux. qu’est-il possible de faire sur ces réseaux ? - Forum Facebook
3 réponses

Bonjour
Est-ce qu'il y a un rapport avec IPv4 - IPv6 pour résoudre mon problème ou je m'égare ?
Non tu t'égares, ta question n'a rien à voir avec la famille d'adresse utilisée par ton application.
avion-f16 a raison, ton problème est davantage une question réseau qu'une question de développement. Toutefois, quand on développe une application réseau, les deux mondes se rejoignent.
urilou777 a bien dégrossi le problème, je me permets d'apporter quelques précisions / clarifications.
Réponse courte
La manière dont est créé un socket au niveau de ton application dépend :
... mais ne dépend pas de la manière dont est routée la machine distante.
Réponse détaillée : rappels sur IP
Rappels sur le routage IP
NB : Dans ce qui suit je fais l'amalgame entre la table de routage et la table de forwarding pour rester simple. La distinction n'est pas utile à ce stade pour comprendre les principes. En toute rigueur, il faut remplacer dans ce qui suit "table de routage" par "table de forwarding".
En terme de routage, une adresse cible est accessible ou non selon qu'elle est routable ou non au sens de la table de routage (voir
Exemple : voici la table de routage de mon PC, connecté à ma box :
La seconde route concerne les IP de mon réseau local. La première route (qui correspond au préfixe 0.0.0.0/0) couvre toutes les adresses IP. On parle de route par défaut. À métriques égales, ton système prend toujours la route dont le préfixe est le plus spécifique pour une adresse donné. Cela signifie que le système utilisera en priorité la seconde route (pour les IPs de mon réseau local) et sinon la première route.
Dans cette table de routage, on voit l'IP 192.168.0.254, qui est celle de ma box. On parle de passerelle. Une passerelle est juste une machine supposée être en mesure de relayer le trafic vers la destination cible. Cette passerelle doit être routable (et elle l'est grâce à la seconde route). Ainsi, on voit qu'en deux routes, on arrive à réellement exprimer comment doit être atteint une destination :
De même qu'il y a une table de routage IPv4, il y a une table de routage IPv6. Les adresses IPv6 sont juste d'autres adresses. Sous Linux, la table de routage IPv6 s'affiche avec la commande
Quelque soit la famille d'adresse considérée, un routeur est une sorte de carrefour et comme pour savoir quelle direction prendre, il faut des panneaux indicateurs (routes) rassemblés dans la table de routage :
Toute la beauté du routage IP, c'est qu'une fois la table de routage peuplée, les applications et les utilisateurs ne se préoccupent plus de comment la route a été apprise et de ses détails (éventuelle passerelle, métrique etc). C'est le système qui gère tout, et c'est donc extérieur à l'application.
Pour qu'une IP destination cible soit joignable, il faut :
Les sockets
IP ne se préoccupe pas du transport lié à la communication : pour gérer le débit, les pertes éventuelles, l'ordre d'arrivée des paquets, etc... on utilise souvent par dessus un protocole de transport, traditionnellement soit UDP soit TCP.
Comme plusieurs applications peuvent coexister sur une même machine et qu'il ne faut pas mélanger les différents communications entre elles, on les distingue par un entier, appelé port. Les ports sont normalisés pour les services commun (par exemple 80 pour HTTP, 443 pour HTTPS). En lui-même, le port est juste une convention et n'a aucun impact sur la nature des données qu'on décide de faire véhiculer. C'est juste une convention pratique qui permet de souvent sous-entre le port (par exemple, ton navigateur se connecte implicitement au port 80 si le site est en HTTP et 443 si le site est en HTTPS, mais tu pourrais spécifier le port du serveur dans l'URL du navigateur). Rien n'empêche (même si c'est bizarre) de faire circuler du trafic HTTP sur un autre port, il faut juste que le client et le serveur adoptent la même convention.
Chaque paquet réseau peut être vue comme une sorte de poupée russe.
Si on devait construire manuellement le paquet, ce serait donc extrêmement fastidieux. Heureusement, pour simplifier tout ça, il y a les sockets. Elles servent d'interface entre le développeur et le système pour faire en sorte que le développeur ait le moins de chose possible à spécifier pour préparer le paquet, le reste étant automatiquement "rempli" par le système.
Au moment de créer une socket, le développeur doit choisir :
Enfin, selon que la machine est cliente ou serveur, le socket ne s'ouvre pas de la même façon. C'est inhérent à ce que font un client et un serveur :
Bonne chance
Est-ce qu'il y a un rapport avec IPv4 - IPv6 pour résoudre mon problème ou je m'égare ?
Non tu t'égares, ta question n'a rien à voir avec la famille d'adresse utilisée par ton application.
avion-f16 a raison, ton problème est davantage une question réseau qu'une question de développement. Toutefois, quand on développe une application réseau, les deux mondes se rejoignent.
urilou777 a bien dégrossi le problème, je me permets d'apporter quelques précisions / clarifications.
Réponse courte
La manière dont est créé un socket au niveau de ton application dépend :
- de la famille d'adresse (IPv4 ou IPv6)
- de l'éventuel protocole de transport utilisé (TCP, UDP, aucun)
- du rôle de la machine (client ou serveur)
- le port associé au serveur
... mais ne dépend pas de la manière dont est routée la machine distante.
Réponse détaillée : rappels sur IP
- Une adresse réseau permet sert à identifier une interface (par exemple, une interface wifi, ethernet etc...)
- Dans du développement logiciel, celles-ci sont identifiées par leur adresse IP.
- On peut au choix utiliser des adresses IPv4 (32 bits) ou IPv6 (128 bits). La notation (pointée ou hexadécimale) est arbitraire, ce n'est qu'une manière arbitraire de représenter un champ de bits.
- En pratique une adresse IPv4 est souvent noté sous la forme d'un quadruplet de 4 octets (donc 4 valeurs entre 0 et 2^32-1 = 255)
- En pratique une adresse IPv6 est souvent noté sous forme hexadécimale (8 groupes de 2 octets) avec des abréviations éventuelles
- À chaque réseau est associé une plage d'adresse IP contiguë et qui commencent par les mêmes bits.
- On parle de préfixe IP. Le préfixe 192.168.1.0/24 signifie que les 24 premiers bits (donc les 3 premiers octets) de 192.168.1 sont fixés et le 4e octet est libre : la plage couverte est donc toutes les adresses de 192.168.1.0 à 192.168.1.255 incluses.
- Un préfixe peut aussi être noté sous forme de masque. Les bits du masque valent 1 quand pour signifier que le bit correspondant de l'adresse est figé, 0 sinon. Le préfixe 192.168.1.0/24 correspond donc au couple (adresse, masque) (192.168.1.0, 255.255.255.0)
Rappels sur le routage IP
NB : Dans ce qui suit je fais l'amalgame entre la table de routage et la table de forwarding pour rester simple. La distinction n'est pas utile à ce stade pour comprendre les principes. En toute rigueur, il faut remplacer dans ce qui suit "table de routage" par "table de forwarding".
En terme de routage, une adresse cible est accessible ou non selon qu'elle est routable ou non au sens de la table de routage (voir
ip routesous Linux
route printsous Windows).
- Chaque interface de la machine est attachée à un réseau (on parle de LAN) qui part son masque sous réseau induit un préfixe. Toutes les adresses appartenant à ce préfixe sont directement joignable (c'est-à-dire, sans passerelle). Cela ne veut pas dire que les deux machines sont directement connectés. Par exemple, si tu as deux PCs connectés à ta box, les deux PCs peuvent se joindre "directement" au sens IP bien que le trafic circule au travers de la box. Dans ce cas, la box se comporte comme un switch (équipement de niveau 2, transparent au sens IP).
- Les adresses qui ne correspondant pas aux réseaux locaux associés à tes interfaces doivent être routés par une route additionnelle. Dans ce cas, la box fait office de routeur (équipement de niveau 3, donc présent au sens IP).
Exemple : voici la table de routage de mon PC, connecté à ma box :
(mando@silk) (~) $ ip route
default via 192.168.0.254 dev wlp2s0 proto static metric 600
192.168.0.0/24 dev wlp2s0 proto kernel scope link src 192.168.0.175 metric 600
La seconde route concerne les IP de mon réseau local. La première route (qui correspond au préfixe 0.0.0.0/0) couvre toutes les adresses IP. On parle de route par défaut. À métriques égales, ton système prend toujours la route dont le préfixe est le plus spécifique pour une adresse donné. Cela signifie que le système utilisera en priorité la seconde route (pour les IPs de mon réseau local) et sinon la première route.
Dans cette table de routage, on voit l'IP 192.168.0.254, qui est celle de ma box. On parle de passerelle. Une passerelle est juste une machine supposée être en mesure de relayer le trafic vers la destination cible. Cette passerelle doit être routable (et elle l'est grâce à la seconde route). Ainsi, on voit qu'en deux routes, on arrive à réellement exprimer comment doit être atteint une destination :
- directement, si l'adresse appartient au préfixe 192.168.0.0/24
- via 192.168.0.254, si l'adresse n'appartient pas au préfixe 192.168.0.0/24
De même qu'il y a une table de routage IPv4, il y a une table de routage IPv6. Les adresses IPv6 sont juste d'autres adresses. Sous Linux, la table de routage IPv6 s'affiche avec la commande
ip -6 route.
Quelque soit la famille d'adresse considérée, un routeur est une sorte de carrefour et comme pour savoir quelle direction prendre, il faut des panneaux indicateurs (routes) rassemblés dans la table de routage :
- . Si dans un routeur domestique, il y a un panneau "autre directions" (la route par défaut).
- Si on considère les routeurs situés dans le cœur de réseau, il n'y a plus de route par défaut. La table de routage peut contenir des centaines de milliers de route (pour faire simple, un préfixe par réseau). Même si ces tables de routages sont peuplées à l'aide de protocoles de routage dédiés (BGP, OSPF, IS-IS...), le principe reste le même : les réseaux adjacents (ce qu'on appelait les LAN) sont directement joignables, pour les autres destination, il faut définir une passerelle (le prochain bond à atteindre pour se rapprocher de la destination).
Toute la beauté du routage IP, c'est qu'une fois la table de routage peuplée, les applications et les utilisateurs ne se préoccupent plus de comment la route a été apprise et de ses détails (éventuelle passerelle, métrique etc). C'est le système qui gère tout, et c'est donc extérieur à l'application.
Pour qu'une IP destination cible soit joignable, il faut :
- qu'elle soit routable de bout en bout (c'est-à-dire que chaque machine IP sache dans quelle direction transmettre le trafic pour atteindre la destination). L'avant dernière machine joint la destination via une route directe, les précédentes via leur passerelle. Il faut bien entendu que le routage soit cohérent de bout en bout (pas de boucles etc.).
- qu'elle ne soit pas filtrées (par un pare-feu, antivirus, proxy) mis en jeu dans la communication
Les sockets
IP ne se préoccupe pas du transport lié à la communication : pour gérer le débit, les pertes éventuelles, l'ordre d'arrivée des paquets, etc... on utilise souvent par dessus un protocole de transport, traditionnellement soit UDP soit TCP.
Comme plusieurs applications peuvent coexister sur une même machine et qu'il ne faut pas mélanger les différents communications entre elles, on les distingue par un entier, appelé port. Les ports sont normalisés pour les services commun (par exemple 80 pour HTTP, 443 pour HTTPS). En lui-même, le port est juste une convention et n'a aucun impact sur la nature des données qu'on décide de faire véhiculer. C'est juste une convention pratique qui permet de souvent sous-entre le port (par exemple, ton navigateur se connecte implicitement au port 80 si le site est en HTTP et 443 si le site est en HTTPS, mais tu pourrais spécifier le port du serveur dans l'URL du navigateur). Rien n'empêche (même si c'est bizarre) de faire circuler du trafic HTTP sur un autre port, il faut juste que le client et le serveur adoptent la même convention.
Chaque paquet réseau peut être vue comme une sorte de poupée russe.
- Chaque enveloppe correspond à un protocole et se matérialise par un header, la structure est généralement normalisée.
- L'ordre dans lequel les headers sont imbriqué découle du modèle OSI (typiquement, un header IP peut envelopper un header TCP qui lui même enveloppe un header HTTP qui lui même enveloppe la donnée à transporter).
- Le contenu de l'enveloppe la plus imbriquées contient la donnée véhiculée est appelé payload.
Si on devait construire manuellement le paquet, ce serait donc extrêmement fastidieux. Heureusement, pour simplifier tout ça, il y a les sockets. Elles servent d'interface entre le développeur et le système pour faire en sorte que le développeur ait le moins de chose possible à spécifier pour préparer le paquet, le reste étant automatiquement "rempli" par le système.
- Du côté du système, selon le socket choisi par le développeur, le système sait quel protocole de transport et quelle interface il devra utiliser pour joindre la destination.
- De son côté, le développeur interagit avec un socket selon le même principe qu'avec un fichier traditionnel. Une fois ouvert, on peut écrire ou lire dedans. Quand on a finit, on n'oublie pas de fermer le socket.
Au moment de créer une socket, le développeur doit choisir :
- la famille d'adresse utilisée pour la communication ;
-
AF_INET
: IPv4 (pour faire communiquer des machines identifiées par des adresses IPv4) -
AF_INET6
: IPv6 (pour faire communiquer des machines identifiées par des adresses IPv4) - Il en existe d'autres (voir
man socket
dans ton moteur de recherche ou dans ton terminal si tu es sous linux):
-
- l'éventuel protocole de transport utilisé pour la communication ;
-
SOCK_STREAM
(TCP) : pour la plupart des applications, pour lesquelles il est important de garantir que les paquet sont acheminés, retransmis de manière transparente en cas de peine, etc. Ce faisant, tout le début du paquet est automatiquement "rempli" par le système (cela inclue notamment tout le header IP). -
SOCK_DGRAM
(UDP) : plutôt pour les applications temps réels ou pour lesquelles les pertes de paquets ne sont pas dramatiques (P2P, VoIP...). Ce faisant, tout le début du paquet est automatiquement "rempli" par le système (cela inclue notamment tout le header IP). -
SOCK_RAW
les sockets raw (très rarement utilisée) : contrairement aux deux premiers types de sockets, on n'utilise pas de protocole de transport, et on écrit l'intégralité du paquet, y compris le header IP si on décide de créer un paquet IP. - Il en existe d'autres (voir
man socket
dans ton moteur de recherche ou dans ton terminal si tu es sous linux).
-
- Si on utilise un socket UDP ou TCP, qui reposent sur la notion de port, il faut aussi indiquer le port associé au serveur mis en jeu (le système gère automatiquement le port côté client).
Enfin, selon que la machine est cliente ou serveur, le socket ne s'ouvre pas de la même façon. C'est inhérent à ce que font un client et un serveur :
- un serveur attend qu'on se connecte à lui
- un client espère pouvoir se connecter à un serveur donné.
Bonne chance

ipv4 et ipv6 ce sont des protocoles qui déterminent comment est codé l'adresse réseau d'une machine, l'un en 32 bits (192.168.0.1) l'autre en hexa (je n'ai pas d'exemple en tête, google)
pour acheminer des données entre 2 réseaux distants il faut tout de même qu'il y ai une connexion physique par le biais d'une passerelle (gateway) géré par le routeur qui donne sur le réseau "global" (internet ou d'entreprise par ex) commun aux 2 réseaux "locaux" et éventuellement un serveur DNS pour ne pas devoir se rappeler de l'adresse de chacune de tes machines.
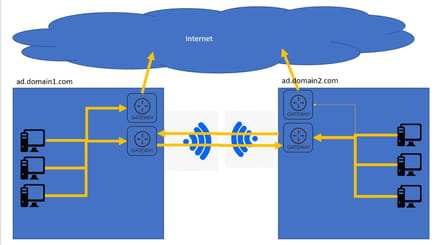
après y'a des histoires de SWITCH, VLAN et pare-feu à configurer pour définir quels autorisateurs de quel sous-réseau par exemple sont autorisés à intéragir entre eux et ça permet de définir des DMZ etc. Une architecture réseau complète quoi.
j'ai des bases en réseaux mais je préfère ne pas t'égarer, je ne suis pas moi même sûr. à développer
pour acheminer des données entre 2 réseaux distants il faut tout de même qu'il y ai une connexion physique par le biais d'une passerelle (gateway) géré par le routeur qui donne sur le réseau "global" (internet ou d'entreprise par ex) commun aux 2 réseaux "locaux" et éventuellement un serveur DNS pour ne pas devoir se rappeler de l'adresse de chacune de tes machines.
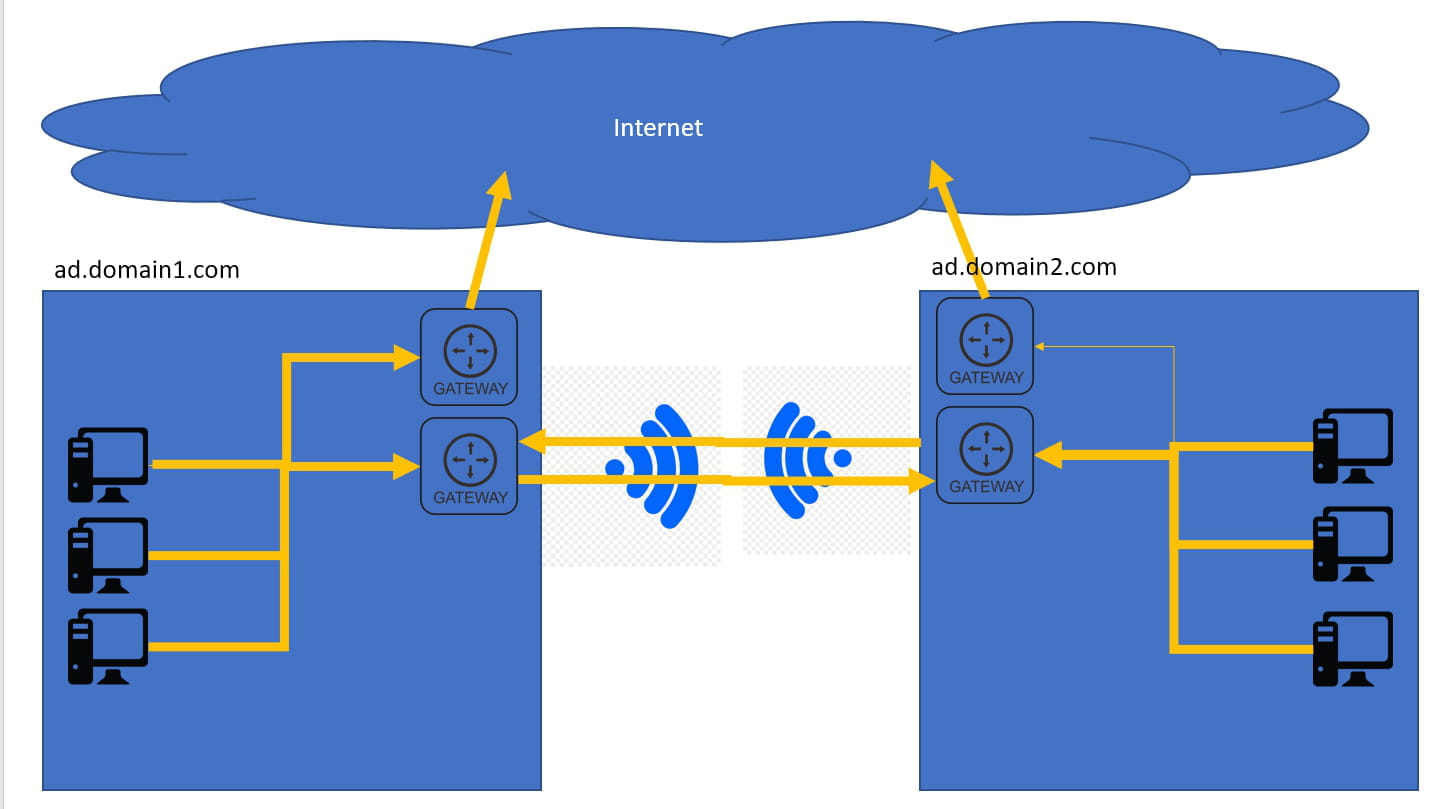
après y'a des histoires de SWITCH, VLAN et pare-feu à configurer pour définir quels autorisateurs de quel sous-réseau par exemple sont autorisés à intéragir entre eux et ça permet de définir des DMZ etc. Une architecture réseau complète quoi.
j'ai des bases en réseaux mais je préfère ne pas t'égarer, je ne suis pas moi même sûr. à développer

Bonjour,
> aucun tuto ou article n'explique comment acheminer des données entre deux réseaus distant
Parce que ce n'est pas le sujet d'un cours de développement, cette question concerne les réseaux et le sujet est bien abordé dans les cours de réseau, car c'est un des objectifs des réseaux...
En tant que développeur, tu vas utiliser la pile réseau existante (à moins de vouloir réinventer la roue) et ouvrir une connexion TCP (ou UDP) sans te soucier des mécanismes de la couche TCP ni même des couches sous-jacentes.
C'est à l'utilisateur qui exécute ton application de s'assurer que sa machine dispose bien d'un accès vers l'IP à laquelle l'application tente de se connecter.
Si les connexions TCP de ton application fonctionnent en réseau local (avec des IP privées), alors cela fonctionnera aussi entre deux machines possédant une IP publique chacune.
Si ta question concerne plus spécifiquement le cas de deux réseaux distants avec des IPv4 privées et derrière des NAT, il faut que tu te renseignes sur ce mécanisme de NAT et ce concept d'IP privées et publiques, et la nécessité de créer une redirection de port depuis l'IP publique du routeur vers l'IP locale de la machine.
Alternativement, on peut utiliser un VPN qui permet de créer un réseau local virtuel entre machines distantes.
Le plus simple est d'utiliser une architecture client/serveur où le serveur possède une IP publique, il est ainsi accessible par tous les clients qui possèdent un accès vers Internet, même si ces clients sont derrière un NAT.
L'architecture pair à pair est fastidieuse avec les NAT (mais pas impossible).
Je te recommande cette excellente vidéo pour apprendre les bases en réseau en seulement une heure :
https://www.youtube.com/watch?v=mgEMGoFIots
> aucun tuto ou article n'explique comment acheminer des données entre deux réseaus distant
Parce que ce n'est pas le sujet d'un cours de développement, cette question concerne les réseaux et le sujet est bien abordé dans les cours de réseau, car c'est un des objectifs des réseaux...
En tant que développeur, tu vas utiliser la pile réseau existante (à moins de vouloir réinventer la roue) et ouvrir une connexion TCP (ou UDP) sans te soucier des mécanismes de la couche TCP ni même des couches sous-jacentes.
C'est à l'utilisateur qui exécute ton application de s'assurer que sa machine dispose bien d'un accès vers l'IP à laquelle l'application tente de se connecter.
Si les connexions TCP de ton application fonctionnent en réseau local (avec des IP privées), alors cela fonctionnera aussi entre deux machines possédant une IP publique chacune.
Si ta question concerne plus spécifiquement le cas de deux réseaux distants avec des IPv4 privées et derrière des NAT, il faut que tu te renseignes sur ce mécanisme de NAT et ce concept d'IP privées et publiques, et la nécessité de créer une redirection de port depuis l'IP publique du routeur vers l'IP locale de la machine.
Alternativement, on peut utiliser un VPN qui permet de créer un réseau local virtuel entre machines distantes.
Le plus simple est d'utiliser une architecture client/serveur où le serveur possède une IP publique, il est ainsi accessible par tous les clients qui possèdent un accès vers Internet, même si ces clients sont derrière un NAT.
L'architecture pair à pair est fastidieuse avec les NAT (mais pas impossible).
Je te recommande cette excellente vidéo pour apprendre les bases en réseau en seulement une heure :
https://www.youtube.com/watch?v=mgEMGoFIots
