
Lecture tableau 2D
Simarre
Messages postés
22
Statut
Membre
-
Simarre Messages postés 22 Statut Membre -
Simarre Messages postés 22 Statut Membre -
Bonjour,
Souhaitant crée des mots nouveaux, j'ai crée un programme qui regarde les suites de caractères dans un mot et les stocks dans un tableau 2D sous la forme suivante:

(Il donne la probabilité de succession des caractères dans des mots et grâce à ce tableau, je peux créer des mots nouveaux.
Mon problème se trouve maintenant à la génération de ces nouveaux mots, j'ai essaye différentes techniques pour crées mais marche à moitiés.
Si quelqu'un aurait une idées pour crée tout les mots possibles grâce au tableau, je suis preneur même sans code c++ :)
Cordialement,
Simarre
Souhaitant crée des mots nouveaux, j'ai crée un programme qui regarde les suites de caractères dans un mot et les stocks dans un tableau 2D sous la forme suivante:
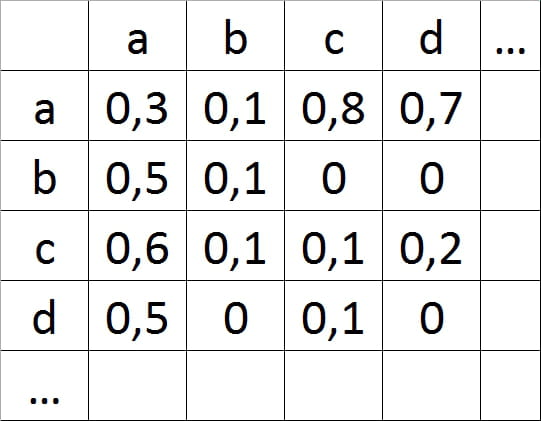
(Il donne la probabilité de succession des caractères dans des mots et grâce à ce tableau, je peux créer des mots nouveaux.
Mon problème se trouve maintenant à la génération de ces nouveaux mots, j'ai essaye différentes techniques pour crées mais marche à moitiés.
Si quelqu'un aurait une idées pour crée tout les mots possibles grâce au tableau, je suis preneur même sans code c++ :)
Cordialement,
Simarre
1 réponse
-
Bonjour,
On peut poser : somme des proba des lettres suivant un 'a' et du cas 'a' fin de mot égale à S('a').
Le plus compliqué est la première lettre du mot, elle devrait être choisie en respectant la probabilité d'avoir avant aucune lettre (en simplifiant on peut la choisir aléatoirement.)
Après de choix d'une lettre x, on tire un nombre aléatoire z dans [0,S(x)[. on parcourt dans la ligne des suivants de x en cumulant jusqu'à atteindre z, on a alors la lettre suivante (ou une fin de mot si on atteint le cas pas de suivant.)
Ceci jusqu'à atteindre une fin de mot.-
D'accord.
J'avais fait une boucle for pour la première lettre de 'a' a 'z' et tant que toute les mots ne sont pas générer, il passe pas a la lettre suivant, après il y a 2 coordonnées 'x' et 'y' avec 2 boucle for qui balaye le tableau mais il y a des bug car ça m'affiche seulement le premier mot de chaque série de 'a' a 'z'.
#include <iostream> #include <string> #include <fstream> using namespace std; int main() { int buffer; double stat[26][26] = {{0}}; string letter[26] = {"a", "b", "c", "d", "e", "f", "g", "h", "i", "j", "k", "l", "m", "n", "o", "p", "q", "r", "s", "t", "u", "v", "w", "x", "y", "z"}; cout << "Extraction du fichier ..." << endl; ifstream i_data("data.txt", ios::in); if(i_data) { string i_word; while(getline(i_data, i_word)) { for(unsigned int i = 0; i < i_word.size(); i++) { string s_word = i_word.substr(i, 1); for(int j = 0; j < 26; j++) { if(s_word == letter[j] && i == 0) { buffer = j; } if(s_word == letter[j] && i > 0) { stat[buffer][j] = stat[buffer][j] + 1; buffer = j; } } } } i_data.close(); } else { cerr << "ERROR 1" << endl; } double sum; cout << "Calcul des probabilites d'apparition ..." << endl; for(int k = 0; k < 26; k++) { for(int l = 0; l < 26; l++) { if(stat[k][l] != 0) { sum = stat[k][l] + sum; } } for(int m = 0; m < 26; m++) { if(stat[k][m] != 0) { stat[k][m] = stat[k][m] / sum; } } sum = 0; } int x, y; int length; int o_buffer; double probability = 1; cout << "Longueur des mots : "; cin >> length; string o_word[length]; cout << "Creation de nouveaux mots ..." << endl; ofstream o_data("word.txt", ios::in); if(o_data) { for(int n = 0; n < 26; n++) { o_buffer = 1; while(o_buffer != 0) { x = n; if(o_buffer == 1) { for(int o = 0; o < length; o++) { if(o == 0) { o_word[o] = letter[n]; } if(o > 0) { for(y = 0; y < 26; y++) { if(stat[x][y] != 0) { o_word[o] = letter[y]; probability = probability * stat[x][y]; x = y; y = 26; } } } } o_buffer++; } if(o_buffer > 1) { for(int p = y + 1; p < 26; p++) { if(stat[x][p] != 0) { o_word[length] = letter[p]; probability = probability * stat[x][p]; x = p; p = 26; } } } for(int a = 0; a < length; a++) { cout << o_word[a]; } cout << " (" << probability << "%)" << endl; o_buffer = 0; } } o_data.close(); } else { cerr << "ERROR 2" << endl; } return 0; }
-
