Différence taille de fichier Windows / Linux... (Samba)
Bonjour bonjour,
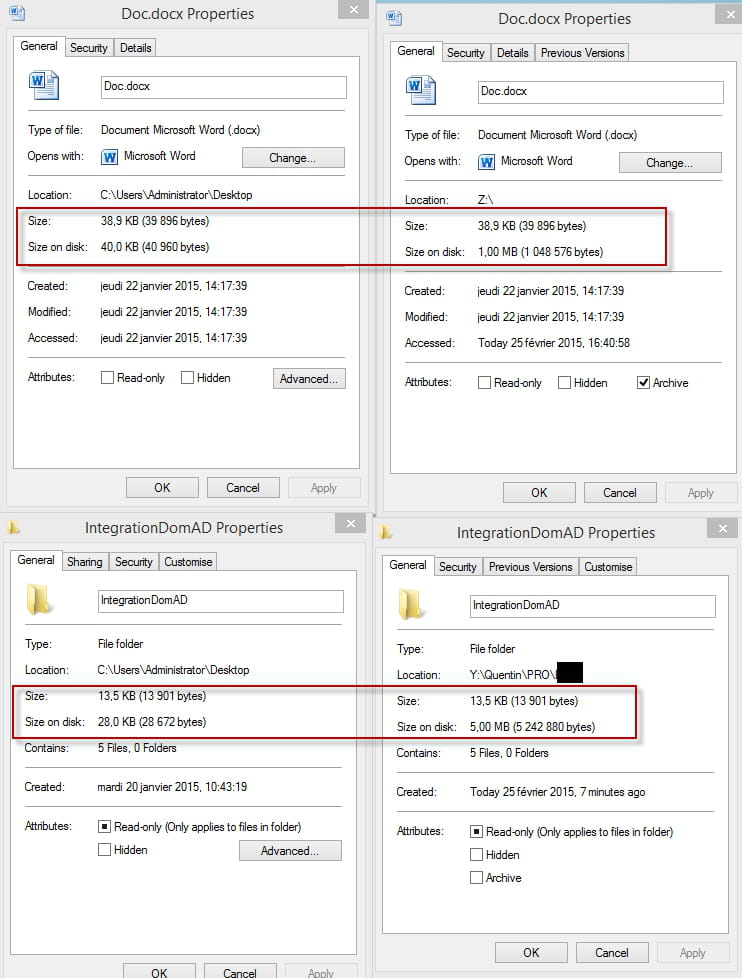
Je dispose d'un serveur SAMBA (ubuntu) qui fait office de serveur de sauvegarde. Le soucis c'est qu'un fichier sous Windows prend visiblement moins de place que sous linux... Enfin dans mon cas.
En fait j'ai l'impression que la différence entre "taille" et "taille sur le disque" son anormale.
Exemple, sous linux un film de 699Mo aura pour taille sur le disque 700Mo.
ça parait dérisoire, mais sur un autre dossier comprenant de nombreux fichiers, je me retrouve avec un écart de près de 90Go (ça passe de 382 sous Windows à 467 sous linux...)
Par contre on peut voir que le résultat de DF -h semble lui plus cohérent... plus proche de la vrai taille que devraient occuper les fichiers...
Vous trouverez ci-joint deux "screenshot"
Quelqu'un pourrait-il me guider... ? :)
Merci d'avance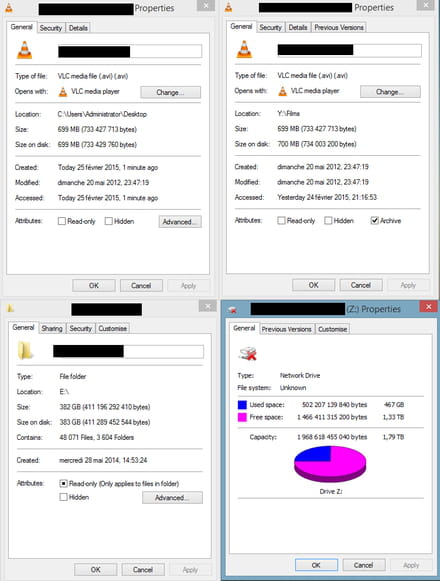

Info supplémentaires :
Mon HDD est un WD Red 3To
Les partitions sont en ext4
Je dispose d'un serveur SAMBA (ubuntu) qui fait office de serveur de sauvegarde. Le soucis c'est qu'un fichier sous Windows prend visiblement moins de place que sous linux... Enfin dans mon cas.
En fait j'ai l'impression que la différence entre "taille" et "taille sur le disque" son anormale.
Exemple, sous linux un film de 699Mo aura pour taille sur le disque 700Mo.
ça parait dérisoire, mais sur un autre dossier comprenant de nombreux fichiers, je me retrouve avec un écart de près de 90Go (ça passe de 382 sous Windows à 467 sous linux...)
Par contre on peut voir que le résultat de DF -h semble lui plus cohérent... plus proche de la vrai taille que devraient occuper les fichiers...
Vous trouverez ci-joint deux "screenshot"
Quelqu'un pourrait-il me guider... ? :)
Merci d'avance


Info supplémentaires :
Mon HDD est un WD Red 3To
Les partitions sont en ext4
3 réponses
-
Pour commencer, si linux accède à un partage samba, le fichier n'est pas physiquement stocké sous linux, puisque celui y accède via le réseau. Donc soit rassuré, si bug il y a, c'est uniquement sur l'affichage des taille qu'il y a un problème.
Si maintenant on considère le stockage d'un fichier F sur une machine windows et une machine linux (considération indépendante de samba), la taille effectivement occupée peut différer. Cela dépend notamment de la taille de bloc utilisée sur le système de fichiers.
https://fr.wikipedia.org/wiki/Bloc_%28disque_dur%29
Bon ensuite j'avoue que tes captures d'écran ne sont pas très claires. La commande linux tapée semble être undf -h
, qui donne donc l'espace occupé pour chaque point de montage, dont les points de montage samba. Vu que le résultat est tronqué on ne sait pas ce que tu as monté dans/mnt/DATA1
ni/mnt/DATA2
et son éventuel rapport avec Z: (le partage samba affiché dans la 4e capture d'écran). Je n'ai pas non plus compris le rôle des 3 premières captures d'écran.
Explication longue : taille de bloc
Un système de fichiers définit la manière dont sont stockées les données sur une partition. Par exemple de la ntfs ou fat32 sous windows, de l'ext4 sous linux, etc.
Lorsqu'un fichier est stocké sur un système de fichier, il occupe un certain nombre de blocs, dont la taille est prédéfinie par le système de fichier et universelle pour tous les fichiers stockant de la données (fichier régulier), par exemple un film, un fichier texte, une photo.
Typiquement sous linux, la taille d'un bloc est de 4Ko. Cela signifie qu'en pratique, un fichier occupe sur le fichier toujours une taille multiple de 4Ko (8Ko, 12Ko, 16Ko, etc...). Cela signifie aussi que si un bloc est grand et que tu as beaucoup de tout petit fichier (mettons quelques octets), chacun d'eux consommant un bloc, il y a beaucoup de "perte". Il ne faut donc pas des blocs trop "grands".
Ok, mais pourquoi des blocs ? Tout simplement parce que dans un système de fichiers tu dois associer un chemin avec une position sur un fichier. Cette information est maintenu dans le système de fichiers par une structure appelée inode. Si cette position était exprimée à l'octet prêt, il faudrait un entier sur encodé sur beaucoup de bits, surtout sur les disques actuels !
Les entiers sont stockés sont souvent stockés en 32 bits, donc la valeur maximale est 2^7-1 = 4194303. Cette valeur serait la plus grande "position" indexable sur cet espace de stockage, ce qui donne en Mo 4194303 / (1024^2) = 4095 soit environ 4Go (digression : note que c'est exactement de ce calcul que vient l'explication : pourquoi une architecture 32 bits non pae ne peut pas gérer plus de 4Go de RAM).
Deux stratégies sont alors possibles :
- soit on utilise des positions sur plus de bits (mais du coup, chaque entrée du système de fichiers coûte "plus cher", et donc on perd de la place pour stocker de la donnée)
- soit on définit une notion de "bloc", et la position d'un fichier est toujours alignée sur le début d'un bloc. Ainsi chaque entrée du système de fichiers coûte le même prix, mais du coup quand un bloc est moins bien rempli, il y a un peu de perte.
En pratique les systèmes de fichiers adoptent cette seconde stratégie.
Bonne chance-
Bonjour,
Merci pour cette réponse très complète.
Cependant, pourquoi sous Windows la taille du fichier est égale à la taille sur le disque, et pas sur linux..?
Il me semble que dans les deux cas j'utilise du 4k en block...
Exemple sur 3 dossiers du partage samba :
http://www.hostingpics.net/viewer.php?id=80238725022015152026.png
Info sur le disque via fdisk...
http://www.hostingpics.net/viewer.php?id=516056resultatfdisk.png
Ce dont j'ai peur c'est qu'au final, mon disque de 3To se voit amputer de 200GB...
PS: Je suis plus Windows que Linuxien... Mais j'essaye. Sinon je me dis qu'à terme je passerai sur un serveur 2012 R2 pour stocker avec déduplication des données... (lorsque j'aurai + de perf sur mon hyperviseur^^)
-
-
Re,
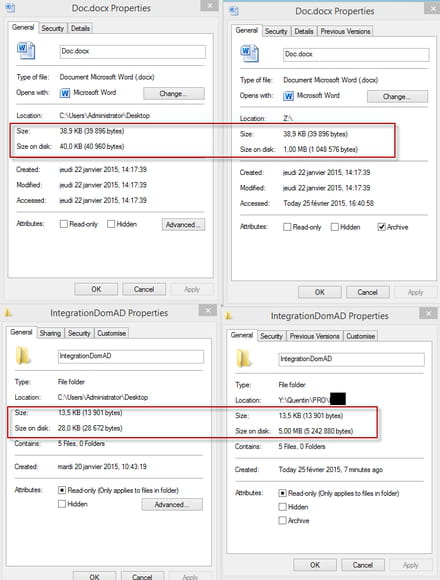
Autre exemple, à gauche les fichiers sous Windows a droite sous linux...
C'est comme si les tailles de block étaient de 1Mo :S... Non? ^^
(5fichiers = 5Mo...)
-
Merci pour ces nouvelles captures d'écran, qui sont beaucoup plus claires pour moi.
C'est bizarre effectivement, je suppose que dans ton exemple, Y: correspond à un partage samba hébergé sous linux ?
Si oui :
1) Quelle est la taille du fichier Doc.docx sous linux ?
2) Est-ce que quand tu récupères le fichier sous windows, il fait la bonne taille ?